Juan Hernández
Fullstack Developer
Geneva, Switzerland
Stock Market Analysis .
Analysis of the main factors driving returns.
Year 2023
Developed Solo
End of Degree Project
Data Analysis
Stocks
Machine Learning
Introduction
One of my favorite reading topics is finance, especially the stock market. As an investor myself, having read dozens of books about stock picking, finance, psychology, and other related topics, I knew that many fields of investing are more an art than a science. This is why I wanted to empirically test some assumptions and study if real-life markets really behave in the way that some textbooks suggest.
Problem
There are many ways to invest and a huge number of investing styles. Many of these styles give contradictory advice, and some don't even provide substantial empirical evidence to support their claims. As I mentioned, investing is somewhat regarded as an art, far from the status of meticulous science. With all these contradictory claims and lack of scientific rigor in some areas, I wanted to test some hypotheses against the real world, in a data-driven approach.
The knowledge I wanted to test was based on the Value Investing theory, which regards stocks as parts of a real business and claims that it is possible to win in the long term by paying attention to the underlying business fundamentals.
Approach
Getting your hands on hundreds of thousands of quality data entries is expensive, as financial data is a very valuable resource. The first challenge was gathering the data, which I achieved via web scraping techniques. This way, I managed to obtain hundreds of data points from the fundamentals of more than 7,000 listed companies, plus some macroeconomic variables. This huge amount of data brought its own problems, forcing me to work with the data in batches and in clever ways, as my computer wasn't nearly powerful enough to handle it all at once.
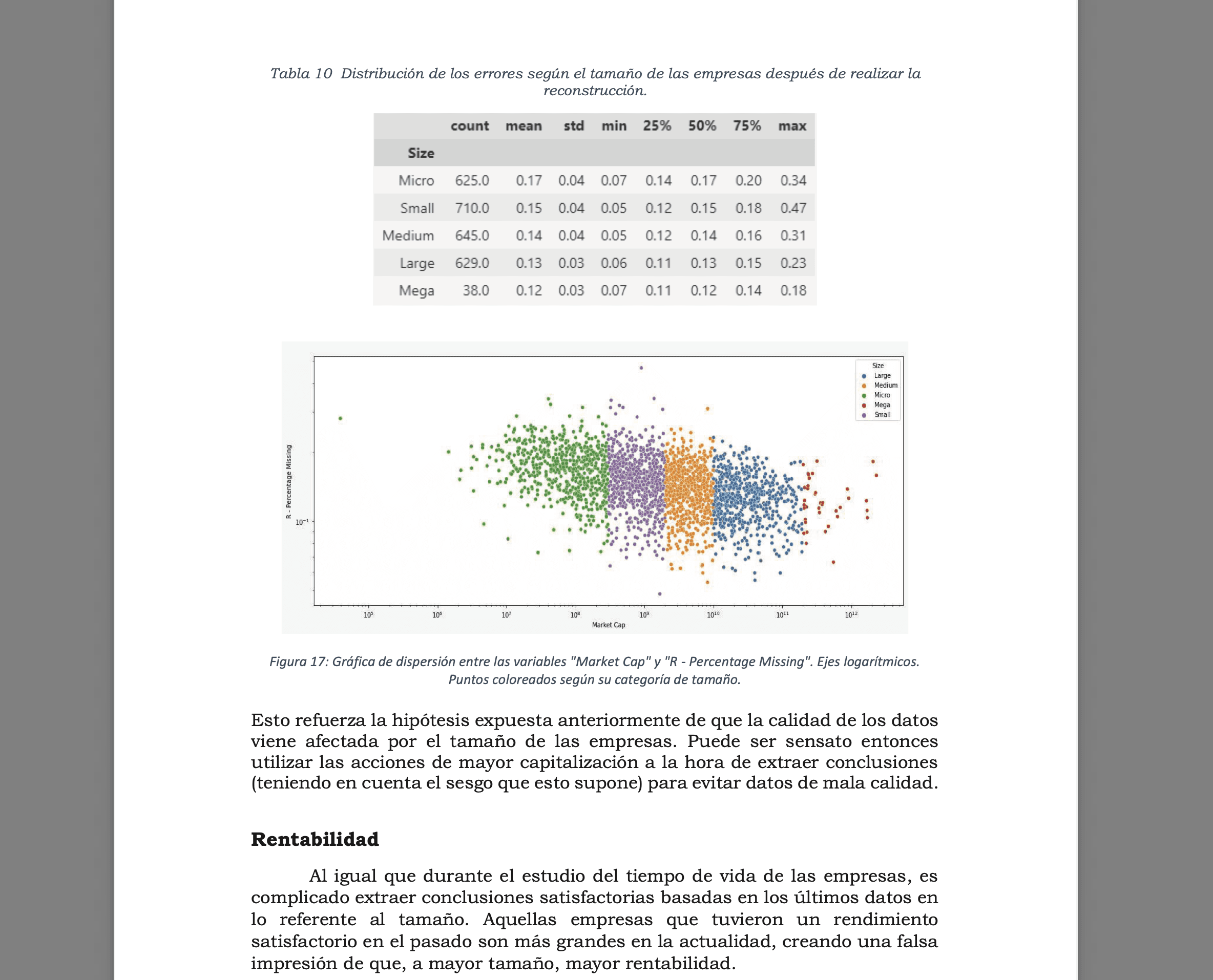
Scraping data gave me access to millions of data points, but the quality was not very good. Sometimes values were missing, or the data was incorrect, so the second challenge was to clean the data to work with a decent dataset. This involved applying K-Means for outlier detection and using accounting principles to clean the data and reconstruct missing items.
Once the data was cleaned, the dataset included thousands of companies with more than 100 factors over a 40-year span. The next step was to perform some exploratory data analysis, test hypotheses, and draw conclusions, all of it segmented by a number of variables such as the size of the company, country, sector, industry, etc.
As an educational exercise, an XGBoost regression was applied to try to find out which fundamental business factors were responsible for the success or failure of companies, again segmenting for more accurate results. After this, some simple models were constructed to try to beat the universe, achieving this objective with great results. But one has to be careful, as the data quality was so poor that these conclusions can hardly be taken seriously. Also, one has to keep in mind that even the stock universe had better returns than the S&P 500, due to survivorship bias caused by our collection method.
As the final task, I developed a simple tool in Python using Streamlit to aid investors in making better investing decisions. This was a small stock analysis tool that scraped the information in real time and showed a stock analysis to the user. Additionally, it also included useful tools such as a stock price calculator using the discounted cash flow method.
Results
As mentioned, the predictive results cannot be taken into account, but the explanatory results were pretty good. Due to the quality of the data, only very clear patterns were concluded, to avoid overfitting to a bad dataset. All of the conclusions nevertheless appeared to be correct, as they were similar to what the literature suggested and in line with current economic and financial theory. Lastly, a very lengthy list of improvements was given to the readers for anyone to expand and improve the analysis.
The main setbacks for the project were the lack of time and money, as this project ended up being 3 to 4 times bigger than what was expected in this kind of work, and in the end, I had to reduce the magnitude of the whole project.